

Jak na webu udělat stránkování z pohledu SEO? Kompletní průvodce

Stránkování je přirozenou součástí každého webu. Používá se u e-shopů v kategoriích při zobrazování produktů (běžně používaná funkce umožňující vypsání velkého počtu produktů), u magazínů v archivaci článků, u diskuzních fór při stránkování vláken či jednotlivých příspěvků a podobně. Jak na stránkování z pohledu SEO?
Na otázku stránkování někdy narazí každý webmaster nebo SEO konzultant. V určitém bodě růstu se obsah na webu prostě musí rozumně rozdělit na sérii očíslovaných stránek. A zde je naším úkolem pomoci vyhledávačům procházet a pochopit vztah mezi těmito stránkami (či URL adresami), aby správně indexovaly (pochopily) tu nejrelevantnější stránku.
Stránkování a SEO, to nejde dohromady – nebo jde?
Možná jste se někde dočetli, že stránkování je špatné pro SEO. Ve většině případů je to však hlavně kvůli špatné práci se stránkováním samotným. Špatně provedené stránkování tedy na webu může způsobit řadu problémů.
Stránkování a duplicitní obsah
Ten při stránkování může relativně snadno vznikat. Například pokud máte současně stránku "Zobrazit vše" a první stránku ze stránkování se stejným obsahem. Nebo máte stránkování bez kanonizace. Na to pozor.
Stránkování a příliš málo obsahu na jednotlivých stránkách
I to je docela častý jev. Hlavně u magazínů (článků). Pokud je na webu rozdělen článek nebo fotogalerie pomocí stránkování (většinou s cílem zvýšit výnosy z reklamy zvýšením počtu zobrazení stránek) a na každé jednotlivé stránce je příliš málo obsahu, je to prostě špatně. Naproti tomu, když stránkováním jdete naproti uživateli, aby mohl lépe a příjemněji konzumovat váš obsah, je to v pořádku. Obsah na každé takové jednotlivé stránce musí být pro uživatele uchopitelný a přínosný. Stránkování krade crawl budget (rozpočet robotů pro procházení webu)
Pokud stránkování uděláte blbě, krade vám zbytečně crawl budget. Robot vyhledávače pak může procházet mnoho stránkovacích stránek, a už mu nezbyde rozpočet na ty opravdu důležité a kvalitní. A to prostě nechcete.
Jak udělat parádní stránkování z pohledu SEO?
Existují určitá pravidla a „best practices“, které byste u stránkování rozhodně neměli opomínat. Pojďme se na ně společně podívat.
Použijte atributy rel="next" & rel="prev"
Pomocí atributů rel="next" a rel="prev" byste měli uvést vztah mezi stránkami, které jsou ve stránkování.
Společnost Google tuto možnost výrazně doporučuje a upozorňuje, že tuto značku považuje za "silnou nápovědu", na kterou byste se měli dívat jako na silné pravidlo. A tak byste s ním měli i zacházet.
Prakticky to znamená, že atributy rel="next" / "prev" jsou považovány spíše za signály, než za směrnice.
Doplňte atributy rel="next" / "prev" ještě i odkazem rel="canonical". Takže /kategorie?stranka=4 by měla být rel="canonical" na /category?stranka=4.
Obrázek řekne více než tisíc slov: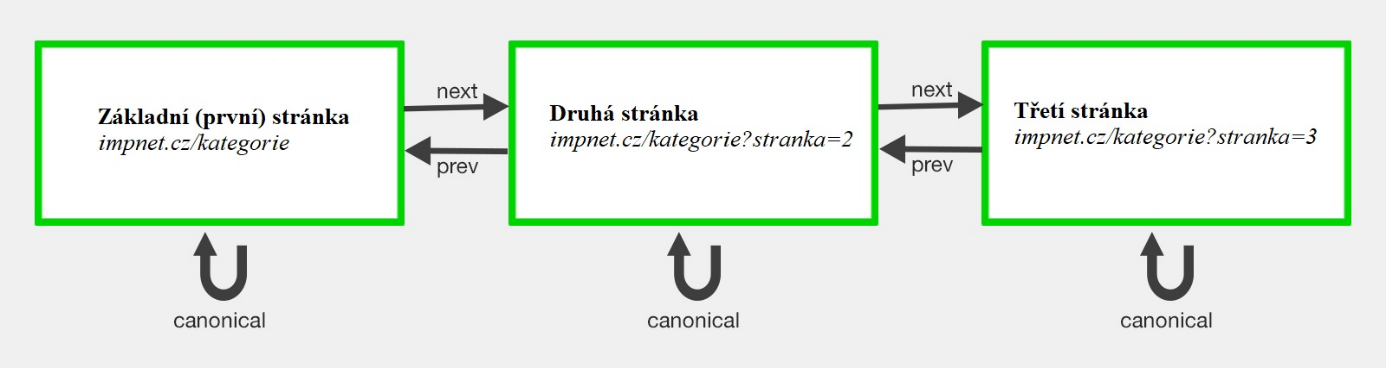
To je doporučený přístup společnosti Google.
A ještě tento případ popíšeme slovně:
- První stránka bude odkazovat na sebe (canonical) a další stránku:
- < link rel="next" href="https://www.impnet.cz/kategorie?stranka=2″>
- < link rel="canonical" href="https:// www.impnet.cz/kategorie">
- Tagy na druhé stránce potom budou:
- < link rel="prev" href="https://www.impnet.cz/kategorie">
- < link rel="next" href="https://www.impnet.cz/kategorie?stranka=3″>
- < link rel="canonical" href="https://www.impnet.cz/kategorie?stranka=2">
- Tagy na třetí stránce budou:
- < link rel="prev" href="https://www.impnet.cz/kategorie?stranka=2″>
- < link rel="canonical" href="https://www.impnet.cz/kategorie?stranka=3">
A takto samozřejmě na všech stránkách ve stránkování.
Poznámka: Pokud má URL adresa další parametry, zahrňte je do atributů rel="prev" / "next", ale nezahrnujte je do rel="canonical". Například:
- < link rel="next" href="https://www.impnet.cz/kategorie?stranka=2&order=newest" />
- < link rel="canonical" href="https://www.impnet.cz/kategorie?stranka=2" />
Těmto chybám se v souvislosti s atributy rel="next" & rel="prev" vyhněte:
- Dávejte je do částistránky, ne do. Pouze vje vyhledávače berou v potaz.
- Nedávejte atributy rel="prev" na první stránku v sérii nebo rel="next" na poslední. Pro všechny ostatní stránky by měly být přítomny oba atributy.
- Dejte si pozor na kanonickou URL adresu vaší hlavní stránky. V canonical by samozřejmě nemělo být page=1.
Upravte titulků a meta descripiton stránek
Přestože by atributy rel="next" a rel="prev" měly ve většině případů způsobit, že Google vrátí hlavní (kořenovou) stránku v SERPu, můžete to vše ještě zlepšit (a vyhnout se tím hlášení "duplicitní meta description" nebo "duplicitní titulky" ve službě Google Search Console) tím, že doplníte odpovídající obsah do těchto elementů.
Tak například:
- titulek kořenové stránky: Automobily BMW v Praze | Brand
- titulek 2 stránkovací stránky: Stránka 2: Automobily BMW v Praze | Brand
Tyto elementy stránkovacích stránek jsou někdy cílevědomě „neoptimální“, aby odradily společnost Google od zobrazování těchto výsledků.
Nezahrnujte stránkovací stránky do XML sitemapy
URL adresy stránkovacích stránek jsou samozřejmě technicky indexovatelné, ale jako takové je indexovat úplně nechceme (aby neplýtvaly zbytečně crawl budget a podobně). Takže je zbytečné je přidávat do XML sitemapy.
Správa parametrů stránkování ve službě Google Search Console
Pokud máte na výběr, udělejte stránkování pomocí parametru, raději než pomocí statických URL adres. Například:
- impnet.cz/kategorie?stranka=2, raději než impnet.cz/kategorie/stranka-2
Proč? Pak můžete nakonfigurovat parametr ve službě Google Search Console v části „Parametry adres URL“, čímž můžete kdykoli přístup vyhledávacích robotů k procházení těchto stránek změnit. A nepotřebujete k tomu ani vývojáře.
Co v případě stránkování fakt NEDĚLAT?
Je několik věcí, které byste v souvislosti se stránkováním opravdu dělat neměli.
Nebudete dělat nic
To, že budete jen sedět a koukat, není úplně nejlepší přístup. Google říká, že "chce uživatelům předkládat nejrelevantnější výsledky, a to bez ohledu na to, zda je obsah rozdělen na více stránek". Neměli byste spoléhat na to, že roboti vyhledávačů poznají, že jde o stránkovaný obsah.
Je proto vždy užitečné poskytnout jasné pokyny pro crawlery, jak chcete, aby indexovali a zobrazovali váš obsah.
Spojíte stránku „Zobrazit vše“ a kanonizaci na první stránku stránkování
Někdy můžete také mít na webu stránku „Zobrazit vše“ (z dané kategorie). Tato verze stránky by pak měla obsahovat celý obsah stránkovacích stránek na jediné adrese URL. V tomto případě, by stránky se stránkováním navíc měly odkazovat pomocí rel=“canonical“ na stránku „Zobrazit vše“, aby konsolidovaly signály o hodnocení. Argumentem je, že uživatelé dávají přednost zobrazení celého článku nebo seznamu kategorií položek na jedné stránce, pokud je načítání této stránky rychlé načítání a navigace na ní je v pohodě.
Takže pokud vaše série stránkovacích stránek má alternativní verzi „Zobrazit vše“, která nabízí lepší uživatelský dojem, vyhledávače pravděpodobně upřednostní tuto stránku pro zařazení do výsledků vyhledávání na rozdíl od relevantní stránky ve stránkování.
To ale pak vyvolává otázku - proč máte stránkovací stránky?
Uděláme to jednoduše.
Pokud můžete poskytnout svůj obsah na jediné adrese URL a zároveň nabízet dobrý uživatelský zážitek z konzumace obsahu, není potřeba stránkování ani verzi „Zobrazit vše“.
Pokud například máte stránku s tisíci produkty, která je nesmyslně velká a její načtení trvá příliš dlouho, pak obsah stránkujte pomocí rel = "next" / "prev". Zobrazit vše v tomto případě není nejlepší volba, protože by stránka nenabídla dobrý uživatelský dojem.
Ale použití atributu rel="next" / "prev" a stránky „Zobrazit vše“ současně neposkytuje Googlu jasný signál pro to, co zobrazit, a bude mít za následek zmatení vyhledávačů. Pro to nedělejte.
Kanonizace na první stránku
Častou chybou je nastavení rel="canonical" ze všech stránkovaných stránek na kořenovou stránku. Může to vypadat jako efektivní způsob, jak upevnit autoritu první stránky v celé sadě stránek. Ale to je zbytečné, když už máte atributy rel = "next" a rel = "prev".
Tento nesprávný způsob kanonizace na kořenovou stránku vede k riziku špatného směrování vyhledávačů do myšlení, že máte pouze jednu stránku výsledků. Googlebot pak nebude indexovat stránky, které se objevují v sérii stránek, ani nebude brát v potaz signály k obsahu propojenému z těchto stránek.
Doporučení od Google je v tomto případě jasné. Každá stránka v sérii by měla mít kanonizaci sama na sebe (pokud nepoužíváte stránku Zobrazit vše).
Parametr Noindex na stránkovacích stránkách
Klasickou metodou pro vyřešení problémů se stránkováním v minulosti byla značka robots noindex, která zabránila indexování stránkovaného obsahu vyhledávači.
Někdy se atribut noindex také kombinoval s rel=“next“ a rel=“prev“.
To je zbytečné. Pouze za výjimečných okolností by se vyhledávač rozhodl vrátit stránkovací stránku do SERPu. Výhody jsou v nejlepším případě teoretické.
Ale to, co možná nevíte je, že dlouhodobý noindex na stránce nakonec může vést vyhledávač Google k tomu, že nebude sledovat odkazy na této stránce. Takže by to mohlo opět způsobit, že obsah spojený se stránkovacími stránkami bude z indexu kompletně odstraněn.
Nekonečné scrollování
Sem tam se na webech objevuje i nekonečné posouvání, kde je obsah předem načten a předán přímo uživateli, když se posouvá (scrolluje) dolů. Uživatelé to mohou ocenit, ale Googlebot? Moc ne.
Googlebot neumí dost dobře simulovat chování uživatele, třeba scrollování. To pak má za následek to, že nemusí být úplně schopen projít veškerý obsah na stránce.
Chcete-li být SEO-přátelský, přeměňte svou nekonečnou scroll stránku na ekvivalentní paginated série, která je přístupná i pokud je zakázán JavaScript.
Lepší přístup z pohledu vyhledávačů je stránkování, které přístupné i pro uživatele, kteří mají vypnutou podporu JavaScriptu.
Závěr
Kanonizace a tagy rel jsou zde od toho, abychom pomohli vyhledávačům lépe pochopit naše stránky. Využívejte je. A využívejte je dobře.
Aktualizce: Jaké je doporučení od Google týkající se stránkování a značek rel = next a rel = prev?
Jak možná víte, tento rok Google oznámil, že atributy pro označení stránkování na webu rel = next a rel = prev již nejsou podporován. Jasně, ale co teď? Jak zajistíte, že Google dokonale pochopí obsah vašich stránek?
Na toto téma se dříve rozpovídal John Mueller ze společnosti Google. Zde je několik bodů, které z jeho povídání vzešlo:
- Společnost Google bere jako lepší variantu umístění všech produktů na jedné stránce. Pokud ale máte na webu stránkování, a vaši uživatelé s ním mají dobré zkušenosti a i vy jste s jeho provedení spokojeni, neměňte to.
- Dle slov Muellera společnost Google už roky tyto atributy nijak nepodporovala, takže se v tomto směru vlastně nic nemění.
- Není zde tedy nic, co potřebujete měnit.
- Rozhodně to není případ, kdy musíte odstranit všechny stránkovací stránky.
- Stejně tak to není případ, kdy potřebujete rychle ze stránkování udělat jednu obří stránku.
- Použijte nástroje třetích stran, abyste zjistili, zda jsou nějaké problémy s procházením.

Pavel Horelica
SEO konzultant
Pavel Horelica
SEO konzultant email: pavel.horelica@impnet.czPavel je tu od toho, aby vás lidé na internetu našli. Stará se o optimalizaci stránek pro vyhledávače, spravuje PPC kampaně a sleduje webová analytika. Má neustále nové nápady a posouvá váš web kupředu.
Co dalšího píšu?

Technické SEO – 8 nejdůležitějších bodů, na které nezapomínat






















 +420 739 323 974
+420 739 323 974 info@impnet.cz
info@impnet.cz zobrazit na mapě
zobrazit na mapě